This is an continuation of my previous article:
Helping Eye Doctors to see better with machine learning (AI)
In this previous article, I explain the transfer learning approach to train a deep neural network with 94% accuracy to diagnose three kinds of eye diseases along with normal eye conditions. In this article, I will explain a different and a better approach to transfer learning to achieve >98% accuracy at 1/10th of the original training speed.
In this new article, I will provide a background of the previoust implementation and the drawbacks of the previous approach. Next, I will provide an overview of the new approach. Rest of the article will explain the new method in detail with annotated Python code samples. I have posted the links at the end of the article for you to try out the methodology and the new model.
Part 1 – Background and Overview
Transfer learning – using a fully trained model as a whole
The previous article utilized the following method of transfer learning.
- Use InceptionV3 model previously trained with imagenet dataset. Remove the fully connected layers and the classifier at the end of the network. Let us call this model, the base model.
- Lock the base model so that it does not get trained with the training images.
- Attach few fully connected layers and a 4 way softmax classifier at the end of the network that have been randomly initialized.
- Train the network by feeding the images randomly for multiple iterations (epochs).
This model was inefficient for the following reasons:
- Could not achieve state of the art accuracy of 96% but could achieve only 94%.
- Best performing model was obtained after 300 epochs.
- Each epoch took around 12 minutes to train as the image data was fed through the whole InceptionV3 model plus the new layers in every epoch.
- The whole training effort run took 100 hours! (4 days).
- Long training time per epoch made it difficult to explore different end layer topologies, learning rates, and number of units in each layer.
Transfer learning – extract features (bottlenecks), save them and feed to a shallow neural network
In the previous approach, each image was fed to the base model and the output of the base model was fed into the new layers. As the base model parameters (weights) were not updated, we were just doing the same computation in the base model in each epoch!
In the new approach, we use the following methods:
First, we feed all the images (training and validation) to extract the output of the base InceptionV3 model. Save the outputs, i.e, features (bottlenecks) and the associated labels in a file.
Next, build a shallow neural network with the following layers:
- Convolution 2d layer that can take the saved features as input.
- Batch normalization layer to increase speed and accuracy.
- Relu activation.
- Dropout layer to prevent overfitting.
- Dense layer with 4 units (corresponding to 4 output classes) with softmax activation
- Use adam optimizer with learning rate of 0.001.
Next, feed the saved features to the shallow network and train the model. Save the best performing model found during training and reduce the learning rate if the validation loss remains flat for 5 epochs.
While making predictions, feed the image first to the InceptionV3 (trained in imagenet), and feed its output to the shallow network. Use the first convolutional layer in the shallow network to create occlusion maps.
This approach gave the following results:
- Best performing model at 99.10% accuracy
- Repeatable accuracy at >98%
- Each epoch take around 1.5 minutes compared to 12 minutes as before.
- Requires only 50 epochs (75 minutes) when compared to 500 epochs (100 hours) to achieve convergence.
- Model size has reduced from 84MB to 1.7MB


In the rest of the article I will explain the new method in detail with annotated Python code samples. I have posted the links at the end of the article for you to try out the methodology and the new model.
Part 2 – Implementation
Extract features using imagenet trained InceptionV3 model
Import the required modules and load the InceptionV3 model
from keras.applications.inception_v3 import InceptionV3, conv2d_bn from keras.models import Model from keras.layers import Dropout, Flatten, Dense, Input from keras import optimizers import os import numpy as np from keras.preprocessing.image import ImageDataGenerator import h5py from __future__ import print_function conv_base = InceptionV3(weights='imagenet', include_top=False)
Import the required modules including conv2d_bn function from Keras applications. This handy conv2d_bn function create a convolution 2d layer, batch normalization, and relu activation.
We then load the InceptionV3 model with imagenet weights without the top fully connected layers.
Extract features by feeding images and save the features to a file
train_dir = '../OCT2017/train' validation_dir = '../OCT2017/test' def extract_features(file_name, directory, key, sample_count, target_size, batch_size, class_mode='categorical'): h5_file = h5py.File(file_name, 'w') datagen = ImageDataGenerator(rescale=1./255) generator = datagen.flow_from_directory(directory, target_size=target_size, batch_size=batch_size, class_mode=class_mode) samples_processed = 0 batch_number = 0 if sample_count == 'all': sample_count = generator.n print_size = True for inputs_batch, labels_batch in generator: features_batch = conv_base.predict(inputs_batch) if print_size == True: print_size = False print('Features shape', features_batch.shape) samples_processed += inputs_batch.shape[0] h5_file.create_dataset('features-'+ str(batch_number), data=features_batch) h5_file.create_dataset('labels-'+str(batch_number), data=labels_batch) batch_number = batch_number + 1 print("Batch:%d Sample:%d\r" % (batch_number,samples_processed), end="") if samples_processed >= sample_count: break h5_file.create_dataset('batches', data=batch_number) h5_file.close() return extract_features('./data/train.h5', train_dir, key='train', sample_count='all', batch_size=100, target_size=(299,299)) extract_features('./data/validation.h5', validation_dir, key='validation', sample_count='all', batch_size=100, target_size=(299,299))
Using Keras image generator functionality we process sample_count images with batch_size images in a batch. The output is stored in a h5 file as values with the following keys:
batches : Total number of batches. Each batch will have batch_size number of images and the last batch might have less than batch_size images.
features-<batch_number> (Example: features-10): extracted features of shape (100, 8, 8, 2048) for batch number 10. Here is the 100 is number of images per batch (batch_size) and (8, 8, 2048) is the feature map. This is the output of mixed 9 layer of InceptionV3.
labels<-batch_number> (Example: labels-10): extracted labels of shape (100, 4) for batch number 10. Here 100 is the batch size and 4 is the number of output classes.
Build and train a shallow neural network
Import the required modules
import keras from keras.applications.inception_v3 import InceptionV3, conv2d_bn from keras.models import Model from keras.layers import Dropout, Flatten, Dense, Input from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau from keras import optimizers import os import numpy as np from keras.preprocessing.image import ImageDataGenerator import h5py import matplotlib.pyplot as plt from __future__ import print_function %matplotlib inline
Setup a generator to feed saved features to the model
def features_from_file(path, ctx): h5f = h5py.File(path, 'r') batch_count = h5f['batches'].value print(ctx, 'batches:', batch_count) def generator(): while True: for batch_id in range(0, batch_count): X = h5f['features-' + str(batch_id)] y = h5f['labels-' + str(batch_id)] yield X, y return batch_count, generator() train_steps_per_epoch, train_generator = features_from_file('./data/train-ALL.h5', 'train') validation_steps, validation_data = features_from_file('./data/validation-ALL.h5', 'validation')
Here, we setup two generators to read features and labels stored in h5 files. We have renamed the h5 files so that we don’t overwrite by mistake during another round of feature extraction.
Build a shallow neural network model
np.random.seed(7) inputs = Input(shape=(8, 8, 2048)) x = conv2d_bn(inputs, 64, 1, 1) x = Dropout(0.5)(x) x = Flatten()(x) outputs = Dense(4, activation='softmax')(x) model = Model(inputs=inputs, outputs=outputs) model.compile(optimizer=optimizers.adam(lr=0.001), loss='categorical_crossentropy', metrics=['acc']) model.summary()
The input shape should match the shape of the saved features. We use Dropout to add regularization so that the model does overfit data. Model summary is shown below:

Typically, one would use only fully connected layers. Here, we use convolutional layer so that we can visualize occlusion maps.
Train the model, save the best model and tune the learning rate
# Setup a callback to save the best model callbacks = [ ModelCheckpoint('./output/model.features.{epoch:02d}-{val_acc:.2f}.hdf5', monitor='val_acc', verbose=1, save_best_only=True, mode='max', period=1), ReduceLROnPlateau(monitor='val_loss', verbose=1, factor=0.5, patience=5, min_lr=0.00005) ] history = model.fit_generator( generator=train_generator, steps_per_epoch=train_steps_per_epoch, validation_data=validation_data, validation_steps=validation_steps, epochs=100, callbacks=callbacks)
Using ModelCheckpoint keras callback, we want to save the best performing model based on validation accuracy. This check and save is done for every epoch (period parameter).
Using ReduceLROnPlateau keras callback we monitor validation loss. If the validation loss remains flat for 5 (patience parameter) epochs, apply a new learning rate by multiplying the old learning rate with 0.5 (factor parameter) but never reduce the learning rate below 0.00005 (min_lr parameter).
If everything goes well, you should have a best models saved in the disk. Please refer to the github repo for the code to display the accuracy and loss graphs.
Evaluate the model
Import the required modules and load the saved model
import os import numpy as np import keras from keras.applications.inception_v3 import InceptionV3 from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array from keras.models import load_model from keras import backend as K from io import BytesIO from PIL import Image import cv2 import matplotlib.pyplot as plt import matplotlib.image as mpimg from matplotlib import colors import requests #set the learning phase to not training K.set_learning_phase(0) base_model = InceptionV3(weights='imagenet', include_top=False) model = load_model('output/model.24-0.99.hdf5')
We need to load the InceptionV3 imagenet trained model as well as the best saved model.
Evaluate the model by making predictions and viewing the occlusion maps for multiple images
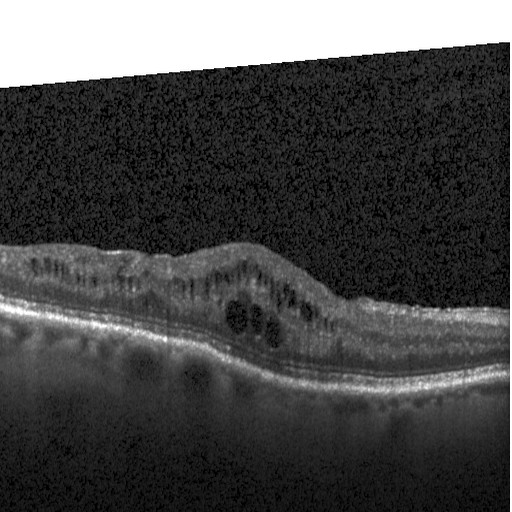
# Utility functions classes = ['CNV', 'DME', 'DRUSEN', 'NORMAL'] # Preprocess the input # Rescale the values to the same range that was used during training def preprocess_input(x): x = img_to_array(x) / 255. return np.expand_dims(x, axis=0) # Prediction for an image path in the local directory def predict_from_image_path(image_path): return predict_image(load_img(image_path, target_size=(299, 299))) # Prediction for an image URL path def predict_from_image_url(image_url): res = requests.get(image_url) im = Image.open(BytesIO(res.content)) return predict_from_image_path(im.fp) # Predict an image def predict_image(im): x = preprocess_input(im) x = base_model.predict(x) pred = np.argmax(model.predict(x)) return pred, classes[pred] image_names = ['DME/DME-30521-15.jpeg', 'CNV/CNV-154835-1.jpeg', 'DRUSEN/DRUSEN-95633-5.jpeg', 'NORMAL/NORMAL-12494-3.jpeg'] for image_name in image_names: path = '../OCT2017/eval/' + image_name print(predict_from_image_path(path)) grad_CAM(path)
While making predictions, we need to feed the image to the base model (InceptionV3) and then feed its output to our shallow model.

The above image shows which part of the image did the model look at to make the prediction.
The Gradient-weighted Class Activation Mapping (Grad-CAM) technique is being used to produce these occlusion maps. For the grad_CAM source and code to show incorrect predictions, refer to the github repo.
Part 3 – Summary and Download links
In this article, I showed how to feed all the images (training and validation) to extract the output of the base InceptionV3 model. We saved the outputs, i.e, features (bottlenecks) and the associated labels in a file.
We created a shallow neural network, fed the saved features to the shallow network and trained the model. We saved the best performing model found during training and reduced the learning rate if the validation loss remains flat for 5 epochs.
We made predictions by first feeding the image to the InceptionV3 (trained in imagenet), and then fed its output to the shallow network. Using the first convolutional layer in the shallow network we created occlusion maps.
This approach gave the following results:
- Best performing model at 99.10% accuracy
- Repeatable accuracy at >98%
- Each epoch take around 1.5 minutes compared to 12 minutes as before.
- Requires only 50 epochs (75 minutes) when compared to 500 epochs (100 hours) to achieve convergence.
- Model size has reduced from 84MB to 1.7MB
Full source code along with the best performing model is available at:
https://github.com/shivshankar20/eyediseases-AI-keras-imagenet-inception
Want to know details about the eye diseases and how to setup a GPU based hardware for your training? Please refer to my first article:
Helping Eye Doctors to see better with machine learning (AI)
I hope enjoyed reading the article! Please share your feedback and experience.